
Based on research by Gartner and McKinsey & Co., Accepted by IEEE.
Forecast
Optimize
Control
Reduce
Forecast
Forecast
Your
Enterprise's
AI Cost
in
Real Time
Trusted by 250+ enterprises to manage Enterprise AI & high-performance GPU infrastructure.
Perrtain. by Pillar Economics Group
Try Live ↓

Backed by the best








Perrtain is not accessible through mobile devices. This is to preserve product quality, and we're sorry for the inaccessability. Please Visit https://pillareconomicsgroup.com/perrtain using your desktop to access Perrtain.
//
Real-Time AI FinOps
//
Real-Time AI FinOps
See live. Act fast. Control AI cost.
Full-stack cost visibility
Unify cloud, GPUs, models, and APIs into one real-time financial view.
Full-stack cost visibility
Unify cloud, GPUs, models, and APIs into one real-time financial view.
True cost attribution
Track spend per workload, model, team, and environment — down to the minute.
True cost attribution
Track spend per workload, model, team, and environment — down to the minute.
Live optimization levers
Adjust GPU allocation, models, and inference settings w/ instant cost impact.
Live optimization levers
Adjust GPU allocation, models, and inference settings w/ instant cost impact.
Idle cost detection
Identify underutilized GPUs, memory waste, and inefficiencies as they occur.
Idle cost detection
Identify underutilized GPUs, memory waste, and inefficiencies as they occur.
Forecast with confidence
Project AI spend based on usage growth, model mix, and scaling patterns.
Forecast with confidence
Project AI spend based on usage growth, model mix, and scaling patterns.
Enterprise-grade governance
Set policies, control budgets, enforce cost discipline across teams.
Enterprise-grade governance
Set policies, control budgets, enforce cost discipline across teams.
Perrtain's Exceptional Integrations Ecosystem
The dashboard is built with data from: Cloud & Specialized GPU Providers, External LLM & Foundation Model APIs, Hardware Accelerators, Inference & Serving Engines, and Orchestration & Context platforms your enterprise uses every single second to support it's operation.

AWS

GCP

Azure

CoreWeave

Lambda Labs

RunPod

OCI

OpenAI

Anthropic

Google Vertex

Gemini
Amazon Bedrock

Azure OpenAI

Mistral

Cohere

Groq

Huggingface

NVIDIA

AMD Instinct

Google TPUs
AWS Trainium

vLLM

TensorRT-LLM

TGI

Triton Inference Server

Ray Serve

Ollama

Kubernetes

Karpenter

Prometheus

OpenTelemetry

Apache Kafka
//
Use cases
//
Use cases
One tool. Every use case. Perrtain.
Real-Time Stats
Live AI Spend
GPU Fleet
Models & Testing
Integrations
and more...

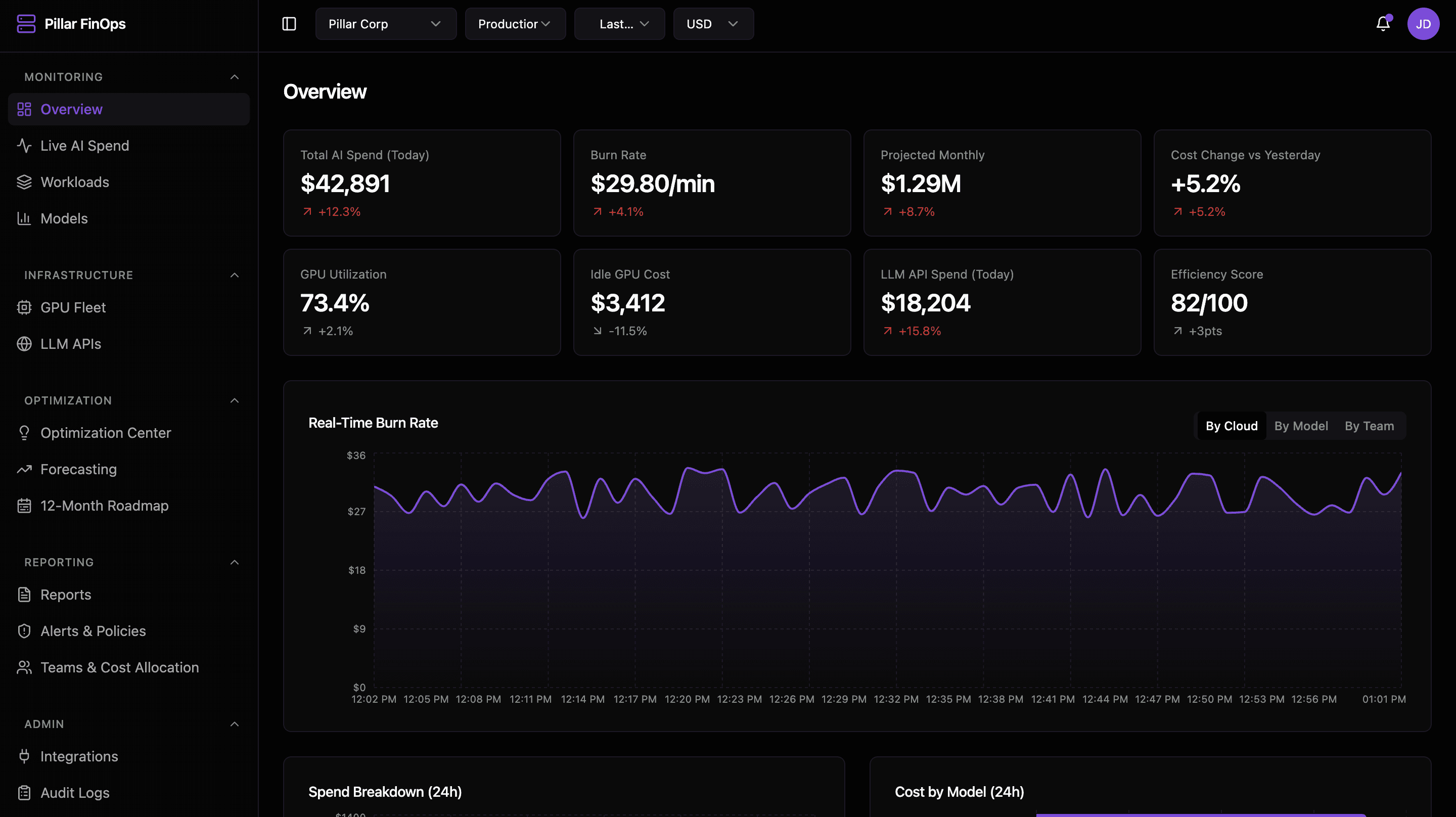
Real-Time Stats
Live AI Spend
GPU Fleet
Models & Testing
Integrations
and more...
Perrtain. by Pillar EG


Subscribe to Perrtain Newsletter!
Clear, practical insights on controlling costs, risk, and value as enterprise AI scales.
Perrtain's Exceptional Integrations Ecosystem
The dashboard is built with data from: Cloud & Specialized GPU Providers, External LLM & Foundation Model APIs, Hardware Accelerators, Inference & Serving Engines, and Orchestration & Context platforms your enterprise uses every single second to support it's operation.
AWS
GCP
Azure
CoreWeave
Lambda Labs
RunPod
OCI
OpenAI
Anthropic
Google Vertex
Gemini
Amazon Bedrock
Azure OpenAI
Mistral
Cohere
Groq
Huggingface
NVIDIA
AMD Instinct
Google TPUs
AWS Trainium
vLLM
TensorRT-LLM
TGI
Triton Inference Server
Ray Serve
Ollama
Kubernetes
Karpenter
Prometheus
OpenTelemetry
Apache Kafka